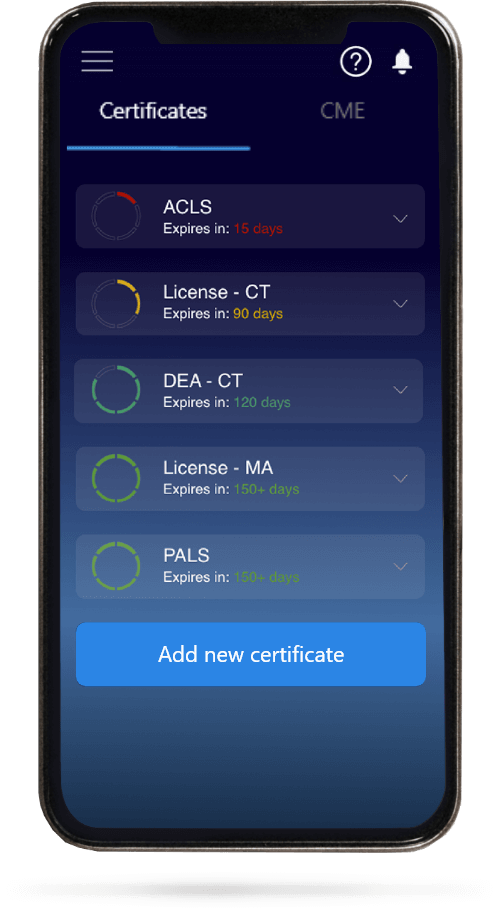
Researchers from Cleveland Clinic and Cornell University have developed free software and web databases to help identify key protein protein interactions to treat with medicine, and get it out into the public.
PIONEER (Protein-protein Interaction interface prediction) is the computational tool used. A recently published Nature Biotechnology article demonstrates how PIONEER was used to help identify potential drug targets for dozens of cancers and other complex diseases. But it is not always enough on its own, says study co-lead author, Ph.D., Cleveland Clinic’s Genome Center director Feixiong Cheng.
“In theory, making new medicines based on genetic data is straightforward: “The mutated genes make the mutated protein,” as Dr. Cheng puts it. “Blocking the interaction between a healthy protein and the protein being misfolded isn’t actually quite so simple as it sounds, but we try to create molecules that stop these proteins from disrupting critical biological processes by blocking them from talking to healthy proteins.”
One condition can have multiple interactomes arising from one differently mutated protein that certainly can be mutated in many ways. That leaves drug developers with tens of thousands of potential disease interactions from which to choose — after they produce the list from the affected protein’s physical structures.
To help genetic/genomic researchers and drug developers better identify the most promising protein protein interactions, Dr. Cheng teamed up with Haiyuan Yu, Ph.D., director of the Cornell University Center for Innovative Proteomics, to develop an artificial intelligence (AI) tool. The group integrated massive amounts of data from multiple sources including:
More than 50,000 informative cancer variants among individuals with rare disease, or cancer acquired later in life, contrasting with a significantly fewer number of disease causing variants in individuals with rare disease.
Almost 100,000 people who had (or have) rare disease or cancer, and compared to about 50,000 people with rare disease or cancer, perhaps due to insulating effects of consanguinity. By virtue of their resulting database, researchers can browse the interactome for over 10,500 diseases, from alopecia to Von Willebrand Disease.
By inputting a disease-associated mutation into PIONEER, researchers can obtain a ranked list of protein-protein interactions that help cause the disease and are therefore potential targets for drug therapy. Search for a disease name to get a list of possible disease causing protein interactions scientists can then pursue.
Designed to assist biomedical researchers who focus on nearly any disease, PIONEER helps them to achieve their goals within categories spanning autoimmune, cancer, cardiovascular, metabolic, neurological and pulmonary. The team checked the database’s predictions in the lab, performing almost 3,000 mutations on over 1,000 proteins and 6,900 protein-protein interaction pairs.
The team also demonstrated that their model’s protein-protein interaction mutations can predict:
- Outcomes of chemotherapy and Radiation therapy in different types of cancer including sarcoma, a cancer that is rare but known to be lethal.
- Cancer drug’s efficacy from different database pharmacogenomic.
The researchers also relied on statements to confirm from other experimental data that protein–protein interaction mutations between the proteins, NRF2 and KEAP1 can be taken as a prognostic biomarker of tumour growth of lung cancer and therefore provides a novel target for the development of targeted cancer therapy.
“The costs required in the interactive research is a major undertaking by most genetic researchers,” contributes Dr. Cheng. “It is our hope that with PIONEER, these elements can be solved computationally to alleviate this labour and allow more scientists to endow new therapies.”
Reference: Xiong D, Qiu Y, Zhao J, Zhou Y, Lee D, Gupta S, et al. A structurally informed human protein–protein interactome reveals proteome-wide perturbations caused by disease mutations. Nature Biotechnology